

続・ニューラルネットワークを構築してみました
はじめに

モデルの概要
ニューラルネットワークの構築は、Kerasの サンプルソースコードを参考にしています。
このサンプルソースコードは、MNISTのデータセットを文字認識するためのサンプルで、畳み込み層2層と全結合層2層で構成される畳み込みニューラルネットワークが構築できます。
サンプルの構成で、ひらがな文字認識は実現することはできそうでした。
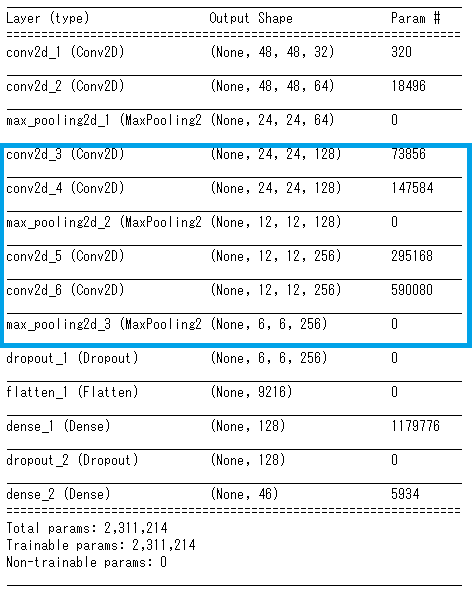
しかし、使用するひらがなの学習データのサイズ(48×48)は、MNISTの画像データのサイズ(28×28)の2倍弱の大きさがあるため、畳み込み層を追加することで、より複雑な特徴を抽出ができ、精度を上げることができると考えました。
そこで今回は、
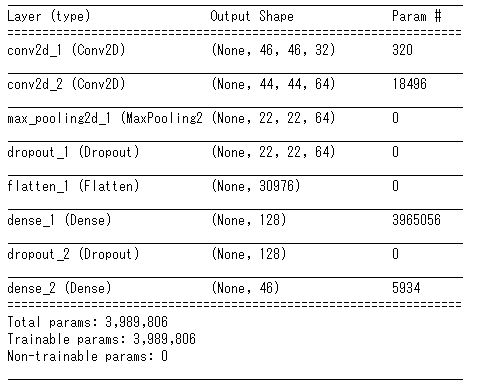
①サンプルと同じ構成のモデル
②畳み込み層を4層追加したモデル
の2種類のモデルを作成しました。
①のモデルの可視化
②のモデルの可視化(青枠が追加部分)
学習データ
学習データは前回と同様です。
文字画像サイズ:48×48ピクセル(グレースケール)
文字種類:濁音、半濁音、「ゐ」、「ゑ」を除く46文字
学習データ:各文字1000個
テストデータ:各文字100個
※学習データ、テストデータともにランダムで抽出しています。
用意された画像データが1100個に満たない文字は、学習データに一部同一データを使用することで個数をそろえています。
文字認識させる画像データ
Windowsの「ペイント」で手書きのひらがな文字を各2個、以下の3種類のパターンに対して作成し、
合計276文字の手書き文字データを用意しました。
- 細字(1px)
- 太字(8px)
- 太字(8px、行書風)
※学習データが行書体に近いため、行書体に近い文字も認識させました。
文字認識させる画像データのイメージ
![]()
![]()
![]()
学習結果
どちらのモデルも、30回学習を行いました。
①、②ともに正解率が高いモデルが作成できました。
①の学習結果(一部抜粋)

②の学習結果(一部抜粋)

acc:学習データの正解率、loss:学習データの損失、val_acc:テストデータの正解率、val_loss:テストデータの損失
認識結果

学習結果に比べると認識率は低い結果になりました。
これは、学習データに細字や楷書体のデータが少ないためで、学習データのパターンを増やすことで、
精度を向上させることができると考えられます。
また、①と②の結果を比較すると②のモデルの方が、全体的に認識率が高い結果となりました。
理論的にはまだわからない部分が多いですが、モデルをチューニングすることで、認識率が変わることも実感できました。
まとめ
今回はニューラルネットワークのライブラリであるKerasを使ってひらがな文字認識をおこない、ニューラルネットワークにおける画像認識の基礎的な仕組みを理解することができました。
今後は、理論的な理解も深めていきたいと思います。

- 当ページの人物画像はNIGAOE MAKERで作成しました。

技術開発推進部ゆりちゃんからのお願い顔マークを押して、技術ブログの
感想をお聞かせください^^